- į¬ėŅųµŻ║▒ŠšŠĘųŽĒį¬ėŅųµŽÓĻP┘YėŹŻ¼┘YėŹāH┤·▒Ēū„š▀ė^³c┼cŲĮ┼_┴ół÷¤oĻP,āH╣®ģó┐╝.
ŽÓą┼╩╣ė├▀^DeepSeek-R1─Żą═Ą─╚╦Ż¼ī”ė┌╦³į┌Įo│÷┤░Ėų«Ū░Ą─╦╝┐╝▀^│╠▓ó▓╗─░╔·Ż¼▀@ę▓╩Ū░³║¼DeepSeek-R1į┌ā╚Ą─┤¾ą══Ų└Ē─Żą═Ż©LRMŻ¼LargeReasoningModelŻ®éõ╩▄═Ų│ńĄ─įŁę“ų«ę╗ĪŻ
╚╗Č°Ż¼ė╔╠O╣¹╣½╦Š┴∙╬╗蹊┐╚╦åTĮM│╔Ą─łFĻĀģsī”┤╦╠ß│÷┴╦┘|ę╔ĪŻ═©▀^ūī─Żą═ĮŌ┤Ė„ĘNųiŅ}Ż¼čąŠ┐łFĻĀ░l¼FDeepSeek-R1Īóo3-mini║═Claude-3.7-Sonnet-Thinking▀@Äū┐ŅŪ░čž┤¾ą══Ų└Ē─Żą═į┌│¼▀^─│ę╗Å═ļsČ╚ķōųĄų«║¾Ż¼╦³éāĄ─£╩┤_┬╩Ģ■│÷¼F╚½├µ▒└ØóĪŻ

łD|ŽÓĻPšō╬─Ą─┴∙╬╗ū„š▀Ż¼ėęČ■×ķ╦_├ūĪż▒Š╝¬ŖWŻ©SamyBengioŻ®Ż©üĒį┤Ż║┘Y┴ŽłDŻ®
X╔Žėąę╗├¹ŠWėč┐éĮYĘQŻ¼╠O╣¹▀@╩Ū«ö┴╦ę╗┤╬╝ė└’Īż±RÄņ╦╣Ż©GaryMarcusŻ®Ż¼ŲõīŹ╝ė└’Īż±RÄņ╦╣▒Š╚╦ę▓į┌ŅIėó░l╠¹┐ŽČ©┴╦╠O╣¹▀@Ų¬šō╬─ĪŻ╦¹īæĄ└Ż║Ī░╠O╣¹╣½╦ŠūŅą┬░l▒ĒĄ─ĻPė┌┤¾šZčį─Żą═ųąĪ«═Ų└ĒĪ»─▄┴”Ą─šō╬─ŅHŠ▀š║│┴”ĪŻ╬ęį┌ę╗Ų¬ų▄─®ķL╬─ųąĮŌßī┴╦ŲõųąĄ─įŁę“Ż©▓ó╠Įėæ┴╦ę╗ĘN┐╔─▄Ą─Ę┤ī”ęŌęŖŻ®Ż¼ęįšf├„×ķ║╬┤¾╝ęŲõīŹ▓╗æ¬ĖąĄĮ╠½▀^¾@ėĀĪŻĪ▒
į┌╝ė└’Īż±RÄņ╦╣Ą─Ī░ų▄─®ķL╬─Ī▒└’╦¹īæĄ└Ż║Ī░▀@Ų¬╠O╣¹╣½╦ŠĄ─ą┬šō╬─▀Mę╗▓Įū¶ūC┴╦╬ę▒Š╚╦Ą─┼·įuė^³cŻ║╝┤▒ŃūŅą┬čą░lĄ─╦∙ų^Ī«═Ų└Ē─Żą═Ī»ęčĮøĄ³┤·│¼įĮo1░µ▒ŠŻ¼Ą½į┌ØhųZ╦■Ą╚ĮøĄõå¢Ņ}╔ŽŻ¼╦³éāę└╚╗¤oĘ©īŹ¼FĘų▓╝═Ō┐╔┐┐═Ų└ĒĪŻī”ė┌─Ūą®╝─ŽŻ═¹ė┌Ī«═Ų└Ē─▄┴”Ī»╗“Ī«═Ų└ĒĢrėŗ╦ŃĪ»─▄ūī┤¾šZčį─Żą═ųž╗žš²▄ēĪóö[├ōå╬╝āęÄ─ŻöUÅłģsīęīę╩¦öĪŻ©╩╝ĮK¤oĘ©«a│÷┼õĄ├╔ŽĪ«GPT-5Ī»├¹╠¢Ą─╝╝ąg═╗ŲŲŻ®Ą─蹊┐š▀Č°čįŻ¼▀@¤oę╔╩ŪéĆē─Ž¹ŽóĪŻĪ▒
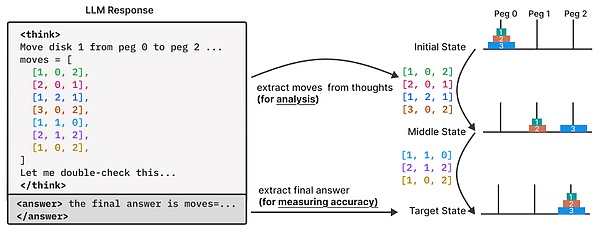
Ż©üĒį┤Ż║┘Y┴ŽłDŻ®
▀@ą®ųiŅ}Š▀ėąęįŽ┬╠ž³cŻ║
Ż©1Ż®─▄ē“╠ß╣®ī”ė┌Å═ļsČ╚Ą─Š½╝Ü┐žųŲŻ╗
Ż©2Ż®▒▄├Ō¼Fėą╗∙£╩ųą│ŻęŖĄ─╬█╚ŠŻ╗
Ż©3Ż®āHąĶę└┘ć├„┤_ĮoČ©Ą─ęÄätŻ¼ÅŖš{╦ŃĘ©╗»═Ų└Ē─▄┴”Ż╗
Ż©4Ż®ų¦│ų╗∙ė┌─ŻöMŲ„Ą─ć└Ė±įu╣└Ż¼─▄ē“īŹ¼FŠ½┤_Ą─ĮŌøQĘĮ░ĖÖz▓ķ║═įö╝ÜĄ─╣╩šŽĘų╬÷ĪŻ
═©▀^īŹūC蹊┐Ż¼╦¹éāĮę╩Š┴╦ĻPė┌«öŪ░┤¾ą══Ų└Ē─Żą═Ą─ÄūéĆĻPµI░l¼FŻ║
╩ūŽ╚Ż¼▒M╣▄┤¾ą══Ų└Ē─Żą══©▀^ÅŖ╗»īW┴Ģ─▄ē“īW┴ĢÅ═ļsĄ─ūį╬ęĘ┤╦╝ÖCųŲŻ¼Ą½╦³éā╬┤─▄×ķęÄäØ╚╬äšķ_░l│÷┐╔Ę║╗»Ą─å¢Ņ}ĮŌøQ─▄┴”Ż¼į┌│¼▀^ę╗Č©Ą─Å═ļsČ╚ķōųĄ║¾Ż¼ąį─▄Ģ■ĮĄų┴┴ŃĪŻ
Ųõ┤╬Ż¼čąŠ┐łFĻĀį┌Ą╚ą¦═Ų└Ēėŗ╦ŃŽ┬ī”┤¾ą══Ų└Ē─Żą═║═ś╦£╩┤¾─Żą═Ą─▒╚▌^Įę╩Š┴╦╚²ĘN▓╗═¼Ą─═Ų└ĒÖCųŲĪŻ
Ą┌ę╗ĘNÖCųŲ╩ŪŻ║ī”ė┌Ė³║åå╬ĪóĮM║Žąį▌^Ą═Ą─å¢Ņ}Ż¼ś╦£╩┤¾─Żą═▒Ē¼F│÷Ė³Ė▀Ą─ą¦┬╩║═£╩┤_ąįĪŻ
Ą┌Č■ĘNÖCųŲ╩ŪŻ║ļSų°å¢Ņ}Å═ļsČ╚Ą─▀mČ╚į÷╝ėŻ¼┤¾ą══Ų└Ē─Żą═½@Ą├┴╦ā×ä▌ĪŻ
Ą┌╚²ĘNÖCųŲ╩ŪŻ║«öå¢Ņ}ļSų°ĮM║Ž╔ŅČ╚Ą─į÷╝ėČ°ūāĄ├Å═ļsĢrŻ¼ā╔ŅÉ─Żą═Č╝ĮøÜv┴╦ÅžŅ^Åž╬▓Ą─ąį─▄▒└ØóĪŻ
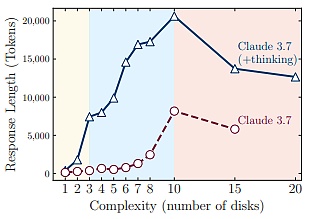
Ż©üĒį┤Ż║┘Y┴ŽłDŻ®
▀@▒Ē├„Ż¼┤¾ą══Ų└Ē─Żą═Ą─═Ų└Ē─▄┴”┤µį┌ę╗éĆĖ∙▒ŠąįŽ▐ųŲŻ║Ųõ═Ų└ĒĢrķgĢ■ļSų°å¢Ņ}Å═ļsČ╚Ą─į÷ķLČ°’@ų°į÷╝ėĪŻ
┤╦═ŌŻ¼═©▀^ī”ųąķg═Ų└Ē▄ē█EĄ─Ęų╬÷Ż¼čąŠ┐łFĻĀ░l¼F┴╦┼cå¢Ņ}Å═ļsČ╚ŽÓĻPĄ─ęÄ┬╔ąį¼FŽ¾Ż¼╝┤į┌▌^║åå╬Ą─å¢Ņ}ųąŻ¼═Ų└Ē─Żą══∙═∙─▄┐ņ╦┘šęĄĮÕeš`ĮŌŻ¼Ą½ģs╚įĢ■Ą═ą¦Ąž└^└m╠Į╦„Õeš`▀xĒŚŻ¼▀@ĘN¼FŽ¾▒Ń╩Ū╚╦éā│ŻšfĄ─Ī░▀^Č╚╦╝┐╝Ī▒ĪŻ
į┌ųąĄ╚Å═ļsČ╚Ą─å¢Ņ}ųąŻ¼─Żą═ąĶę¬Įø▀^ī”┤¾┴┐Õeš`┬ĘÅĮĄ─ÅVĘ║╠Į╦„║¾Ż¼▓┼─▄šęĄĮš²┤_ĮŌĪŻČ°│¼▀^ę╗Č©Ą─Å═ļsČ╚ķōųĄŻ¼─Żą══Ļ╚½¤oĘ©šęĄĮš²┤_ĮŌĪŻ
▒▒Š®Ó]ļŖ┤¾īWĖ▒Į╠╩┌░ūµ├ĖµįVDeepTechŻ¼Ė·╚╦ŅÉ╦╝ŠSĘĮ╩ĮŽÓĮ³Ż¼ī”ė┌Å═ļså¢Ņ}Ż¼ļm╚╗▓╗ų¬Ą└╩▓├┤╩Ūš²┤_Ą─┤░ĖŻ¼Ą½╩Ū║▄ČÓĢr║“ų¬Ą└╩▓├┤╩Ū▓╗š²┤_Ą─ĪŻŠ▀¾wČ°čįŻ¼▀@Ė·Ū¾ĮŌ┐šķg┤¾ąĪėąĻPŽĄŻ¼║åå╬å¢Ņ}Ą─Ū¾ĮŌ┐šķgę“▀ē▌ŗµ£Śl║åČ╠Īó╠žš„Ųź┼õČ╚Ė▀Ż¼š²┤_ĮŌ═∙═∙╠ņ╚╗╠Äė┌╦╝ŠS┬ĘÅĮĄ─Ū░Č╦Ż¼Č°Å═ļså¢Ņ}Ą─ĮŌ┐šķgę“╔µ╝░ČÓŠSČ╚ūā┴┐±Ņ║ŽĪó▀ē▌ŗīė╝ēŪČ╠ūČ°│╩¼FųĖöĄ╝ē┼“├øŻ¼Ū¾ĮŌ┐šķg²ŗ┤¾Ż¼┐═ė^╔Ž▒Ē¼F×ķ╦╝ŠSą“┴ąųąĄ─ŽÓī”║¾ų├ąįĪŻ═Ų└Ē─Żą═Ą─Ī░╦╝ŠSĪ▒ā╚▓┐░l╔·┴╦╩▓├┤Ż┐
蹊┐ųąŻ¼┤¾ČÓöĄīŹ“×Č╝╩Ūį┌═Ų└Ē─Żą═╝░ī”æ¬Ą─ĘŪ═Ų└Ē─Żą═╔Ž▀MąąĄ─Ż¼└²╚ńClaude3.7SonnetŻ©ėą═Ų└Ē/¤o═Ų└ĒŻ®║═DeepSeek-R1/V3ĪŻčąŠ┐łFĻĀ▀xō±▀@ą®─Żą═╩Ūę“×ķ┼cOpenAIĄ─oŽĄ┴ąĄ╚─Żą═▓╗═¼Ą─╩ŪŻ¼╦³éāį╩įSįLå¢╦╝ŠStokenĪŻ
ī”ė┌├┐éĆųiŅ}īŹ└²Ż¼čąŠ┐łFĻĀ╔·│╔25éĆśė▒ŠŻ¼▓ół¾Ėµ┴╦├┐éĆ─Żą═Ą─ŲĮŠ∙ąį─▄ĪŻ
×ķ┴╦Ė³╔Ņ╚ļĄž┴╦ĮŌ═Ų└Ē─Żą═Ą─╦╝┐╝▀^│╠Ż¼čąŠ┐łFĻĀī”╦³éāĄ─═Ų└Ē║██E▀Mąą┴╦╝Üų┬Ą─Ęų╬÷ĪŻ
Ų┌ķgŻ¼╦¹éā═©▀^ųiŅ}īŹ“ףhŠ│Ą─śŗĮ©Ż¼īŹ¼F┴╦ī”─Żą═ūŅĮK┤░Ėų«═ŌĄ─╔ŅČ╚ĮŌ╬÷Ż¼Å─Č°─▄ē“ī”Ųõ╔·│╔Ą─═Ų└Ē▄ē█EŻ©╝┤Ī░╦╝┐╝▀^│╠Ī▒Ż®▀MąąĖ³Š½╝ÜĄ─ė^£y┼cĘų╬÷ĪŻ
Š▀¾wüĒšfŻ¼╦¹éāĮĶų·ųiŅ}─ŻöMŲ„Ż¼ī”─Żą═╦╝ŠS▀^│╠ųą╠Į╦„Ą─ųąķgĮŌ▀Mąą┴╦╠ß╚Ī┼cĘų╬÷ĪŻ
ļS║¾Ż¼╦¹éā┐╝▓ņ┴╦▀@ą®ųąĮŌĄ──Ż╩Į║═╠žš„ĪóŽÓī”ė┌═Ų└Ē▀^│╠ųąĒśą“╬╗ų├Ą─š²┤_ąįŻ¼ęį╝░▀@ą®─Ż╩Į╚ń║╬ļSų°å¢Ņ}Å═ļsČ╚Ą─į÷╝ėČ°č▌ūāĪŻ
ī”ė┌▀@ę╗Ęų╬÷Ż¼čąŠ┐łFĻĀųž³cĻPūó┴╦Claude3.7Sonnet═Ų└Ē─Żą═į┌ųiŅ}ĮMīŹ“×ųą«a╔·Ą─═Ų└Ē║██EĪŻ
ī”ė┌║██Eųą┤_Č©Ą─├┐éĆųąķgĮŌĘ©Ż¼čąŠ┐łFĻĀėøõø┴╦ęįŽ┬ā╚╚▌Ż║Ż©1Ż®Ųõį┌═Ų└Ē▄ē█EųąĄ─ŽÓī”╬╗ų├Ż©░┤┐é╦╝ŠSķLČ╚Üwę╗╗»Ż®Ż¼Ż©2Ż®Įø蹊┐łFĻĀĄ─ųiŅ}─ŻöMŲ„“×ūCĄ─Ųõš²┤_ąįŻ¼Ż©3Ż®ŽÓæ¬å¢Ņ}Ą─Å═ļsČ╚ĪŻ
▀@╩╣Ą├蹊┐łFĻĀ─▄ē“├Ķ╩÷š¹éĆ═Ų└Ē▀^│╠ųąĮŌøQĘĮ░Ėą╬│╔Ą─▀Mš╣║═£╩┤_ąįĪŻ

╚╗Č°Ż¼ī”ė┌Ė³Å═ļsĄ─å¢Ņ}Ż¼▀@ę╗┌ģä▌Ģ■░l╔·ūā╗»Ī¬Ī¬ĮŌøQĘĮ░ĖĄ─£╩┤_ąįĢ■ļSų°╦╝┐╝Ą─═Ų▀MČ°╠ßĖ▀Ż¼ų▒ų┴▀_ĄĮ─│éĆķōųĄĪŻ│¼▀^▀@éĆÅ═ļsČ╚ķōųĄŻ¼į┌Ī░▒└Øó─Ż╩ĮĪ▒Ž┬Ż¼─Żą═Ą─£╩┤_┬╩×ķ┴ŃĪŻ
░ūµ├ĖµįVDeepTechŻ¼─Żą═į┌Å═ļså¢Ņ}ųąąĶę¬ČÓ┤╬═Ų└ĒŻ¼į┌ę╗ų▒ø]ėąš²┤_ĮŌĄ─Ū░╠ߎ┬Ż¼─Żą══Ų└ĒÖCųŲųąėą┐╔─▄▓╔ė├┴╦ČÓ┤╬Ą³┤·═Ų└Ē╔·│╔ą¦┬╩ā×╗»▓▀┬įŻ¼╗“įS╩ŪĘ└ų╣Ą³┤·▀^ČÓĄ─ę╗ĘN┘Yį┤▒Żūo▓▀┬įĪŻę“┤╦Ż¼▒Š┤╬šō╬─ųąĄ─░l¼FąĶę¬Å──Żą═īŹ¼Fīė├µ╚ź▀Mąą╝Üų┬Ą─Ęų╬÷║═“×ūCĪŻ
░ūµ├ųĖ│÷Ż¼┤¾─Żą═Ą─═Ų└Ē▀^│╠▒Š┘|╔Ž╩Ūėøæø─Ż╩ĮĄ─š{ė├ę▓╩Ūėą┐╔─▄Ą─ĪŻī”ė┌DeepSeek-R1Īóo3-mini▀@ŅÉ─Żą═Ż¼Ųõ▒Ē¼FĖ▀Č╚ę└┘ćė¢ŠÜöĄō■ųąėøæø─Ż╩ĮĄ─Ė▓╔wĘČć·Ż¼«öå¢Ņ}Å═ļsČ╚═╗ŲŲėøæø─Ż╩ĮĄ─Ė▓╔wķōųĄŻ©╚ń▒Š┤╬╠O╣¹čąŠ┐łFĻĀįOėŗĄ─┐╔┐žųiŅ}ŁhŠ│Ż®Ż¼─Żą═▒ŃŽ▌╚ļĪ░┴Ń£╩┤_┬╩Ī▒ĀŅæBĪŻ
ļm╚╗▒Š┤╬ųiŅ}ŁhŠ│į╩įSī”å¢Ņ}Å═ļsČ╚▀Mąą╝Ü┴ŻČ╚┐žųŲĄ─╩▄┐žīŹ“ׯ¼Ą½╦³éāāH┤·▒Ē═Ų└Ē╚╬䚥─ę╗ąĪ▓┐ĘųŻ¼┐╔─▄¤oĘ©▓ČūĮĄĮ¼FīŹ╩└Įń╗“ų¬ūR├▄╝»ą══Ų└Ēå¢Ņ}Ą─ČÓśėąįĪŻ
ąĶę¬ųĖ│÷Ą─╩ŪŻ¼▒ŠčąŠ┐ų„ę¬╗∙ė┌║┌ŽõAPIįLå¢ĘŌķ]Ą─Ū░čž┤¾═Ų└Ē─Żą═Ż¼▀@ę╗Ž▐ųŲ╩╣蹊┐łFĻĀ¤oĘ©Ęų╬÷Ųõā╚▓┐ĀŅæB╗“╝▄śŗĮM╝■ĪŻ
┤╦═ŌŻ¼╩╣ė├┤_Č©ąįųiŅ}─ŻöMŲ„ĢrŻ¼čąŠ┐łFĻĀ╝┘įO═Ų└Ē┐╔ęįę╗▓Įę╗▓ĮĄžĄ├ĄĮ═Ļ├└“×ūCĪŻ╚╗Č°Ż¼į┌ĮYśŗ╗»│╠Č╚▌^Ą═Ą─ŅIė“Ż¼▀@ĘNŠ½┤_Ą─“×ūC┐╔─▄ļyęįīŹ¼FŻ¼Å─Č°Ž▐ųŲ┴╦įōĘų╬÷ĘĮĘ©Ž“Ė³ÅVĘ║═Ų└Ēł÷Š░Ą─▀węŲĪŻ
┐éĄ─üĒšfŻ¼čąŠ┐łFĻĀ═©▀^┐╔┐žĄ─ĮŌųiŁhŠ│Ż¼Å─å¢Ņ}Å═ļsČ╚Ą─ĮŪČ╚┐╝▓ņ┴╦Ū░čž┤¾ą══Ų└Ē─Żą═ĪŻ▀@ę╗│╔╣¹Įę╩Š┴╦«öŪ░─Żą═Ą─ŠųŽ▐ąįŻ║╝┤▒M╣▄╦³éāōĒėąÅ═ļsĄ─ūį╬ęĘ┤╦╝ÖCųŲŻ¼Ą½▀@ą®─Żą═į┌│¼▀^╠žČ©Å═ļsČ╚ķōųĄ║¾Ż¼╚į╚╗¤oĘ©░lš╣│÷┐╔Ę║╗»Ą─═Ų└Ē─▄┴”ĪŻčąŠ┐łFĻĀšJ×ķŻ¼▒Š┤╬│╔╣¹╗“įS─▄×ķ蹊┐▀@ą®─Żą═Ą─═Ų└Ē─▄┴”õüŲĮĄ└┬ĘĪŻ
├Ōž¤┬Ģ├„:╠O╣¹ą┬šō╬─Ęų╬÷DeepSeek-R1ė÷ĄĮÅ═ļsČ╚ķōųĄ║¾£╩┤_┬╩▒└Øóå¢Ņ}╬─š┬▐D░lūį╗ź┬ōŠWŻ¼░µÖÓÜwŲõ╦∙ėąĪŻ
╬─š┬ā╚╚▌▓╗┤·▒Ē▒ŠšŠ┴ół÷║═╚╬║╬═Č┘Y░Ą╩ŠĪŻ╝ė├▄žøÄ┼╩ął÷śOŲõ▓©äėŻ¼’LļU║▄Ė▀Ż¼┐╔─▄▓╗▀m║Ž╦∙ėą═Č┘Yš▀ĪŻį┌═Č┘Y╝ė├▄žøÄ┼ų«Ū░Ż¼šł┤_▒Żūį╝║│õĘų┴╦ĮŌ╩ął÷║══Č┘YĄ─’LļUŻ¼▓ó┐╝æ]ūį╝║Ą─žöäšĀŅør║═’LļU│ą╩▄─▄┴”ĪŻ┤╦═ŌŻ¼šłū±čŁ─·╦∙į┌ć°╝ęĄ─Ę©┬╔Ę©ęÄŻ¼ęį╝░ū±╩žĮ╗ęū╦∙║═ÕX░³╠ß╣®╔╠Ą─ęÄČ©ĪŻī”ė┌╚╬║╬ę“╩╣ė├╝ė├▄žøÄ┼╦∙įņ│╔Ą─═Č┘Yōp╩¦╗“Ųõ╦¹ōp╩¦Ż¼▒ŠšŠ▓╗│ąō·╚╬║╬ž¤╚╬ĪŻ
 2025-7-08
2025-7-08
 2025-7-08
2025-7-08
 2025-7-08
2025-7-08
 2025-7-08
2025-7-08
 2025-7-08
2025-7-08
2025-7-08
2025-7-08
2025-7-08
2025-7-08
2025-7-08
2025-7-08
2025-7-08
2025-7-08
2025-7-08
2025-7-08
Copyright © 2021.Company į¬ėŅųµYITB.COM All rights reserved.į¬ėŅųµYITB.COM